Teradata создает экосистему для аналитики больших данных

Год назад Teradata объявила о коммерческой поддержке открытого ПО в области извлечения и анализа больших данных и сейчас активно развивает соответствующую экосистему. Об интеграции всех доступных инструментов, о применении современных подходов и методологий в аналитике и быстром коммерческом эффекте, было рассказано на ежегодном мероприятии из цикла Teradata CTO Roadshow.
Teradata провела очередную встречу в рамках своего технического семинара CTO Roadshow. Мероприятие ежегодно собирает более 100 ИТ-руководителей и специалистов в области больших данных, построения систем их обработки и анализа. В этом году спикеры Teradata делились кейсами и советами по построению хранилищ и «озер» данных, рассказывали об эффективности различных подходов к программированию, об open source решениях, продуктах на их основе, а также об интеграции различных инструментов для работы с данными.
Количество данных, которые нас уже окружают и которые мы генерируем ежесекундно, огромно. Они происходят из большого количества разных источников, интерес специалистов к которым не всегда был одинаковым. Стивен Бробст, главный технический директор компании Teradata, в своем интервью CNews выделил три волны. Первая — анализ так называемых «кликстримов» и транзакций, пользовательского поведения в интернете и особенностей восприятия предлагаемого контента. Следующим этапом стал интерес к социальным данным, которые производят сами пользователи. Под прицел аналитиков попали посты в социальных сетях, распознавание речи, изображений, особенности взаимодействия людей и т.п. Третьей волной больших данных Стивен Бробст называет анализ данных с датчиков, сенсоров и различных измерительных систем — тот самый интернет вещей, который стал самой популярной ИТ-темой. При этом большинство примеров реализации представляют собой, строго говоря, не интернет, а интрАнет вещей, развернутый во внутренней сети организации, и эффективных примеров анализа данных с сенсоров пока немного. Кроме того, информационная безопасность таких систем под большим вопросом.
Третья волна больших данных
Развивая тему третьей волны больших данных, генеральный директор Teradata в России Андрей Алексеенко привел сравнение модели интернета вещей с моделью нервной системы человека, предложенное Массачусетским Технологическим Институтом. На нижнем уровне нервной системы человека находятся нейроны, связанные, с одной стороны, с различными видами рецепторов, реагирующих на внешние разражители и угрозы, а с другой стороны связанные, с актуаторами в виде элементов костно-мышечной системы, которые рефлекторно реагируют в случае получения сигнала. Помимо периферической, у человека есть и центральная НС, которая задействует интеллект и накопленный опыт.
Модель человека
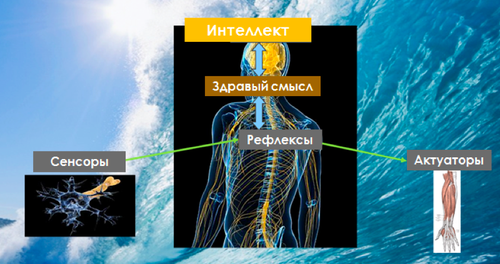
Источник: MIT, 2016
По аналогии общую схему аналитической системы интернета вещей можно представить следующим образом: на нижнем уровне работают работают сенсоры, в реальном времени контролирующие ключевые параметры технического состояния устройства, машины или объекта. В случае их отклонения включается промышленная автоматика, которая используя различные актуаторы и приводит параметры в норму или блокирует устройство во избежании аварии. На следующем уровне накапливаются статистистические данные о техническом состоянии и имевших место инцидентах, на основе которых логично формировать регулярную операционную отчетность, необходимую для принятия управленческих решений. И наконец на верхнем уровне, используя накопленные массивы данных различных видов, могут решаться более сложные, исследовательские и инновационные задачи с применением средств предсказательной и предписывающей «Аналитики вещей» и облачных вычислений.
Модель интернета вещей
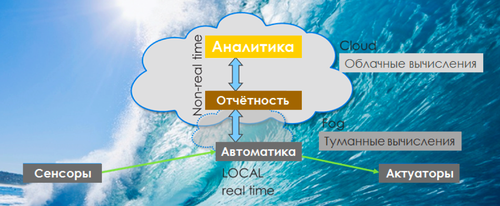
Источник: MIT, 2016
В рамках CTO Roadshow Teradata поделилась со слушателями различными прикладными технологиями и подходами, решающими конкретные специализированные задачи. В частности, Андрей Прохоров, руководитель группы архитекторов российского офиса Teradata, рассказал про обработку потоковых источников данных при помощи Complex Event Processing применительно к масштабным маркетинговым кампаниям. Технология позволяет управлять разнородными потоками сообщений, которые неэффективно напрямую загружать в хранилище данных, так как они требуют предварительной обработки. Сопоставление с другими источниками информации, так называемое «обогащение» данных позволяет принять обоснованное бизнес-решение для своевременного взаимодействия с каждым конкретным пользователем в режиме реального времени.





О практике использования agile-подхода в классических проектах построения хранилищ данных и формирования отчетности рассказал Владимир Филимонов, архитектор решений Teradata Россия. Agile, по мнению эксперта, позволяет существенно сократить объем ненужной работы, который образуется из-за недопонимания между командой и заказчиком. Избыточное документирование различных требований к проекту, характерное для классического «водопада», также может приводить к бесполезным разработкам, целесообразность которых на начальном этапе неочевидна. На вопрос о том, в каких проектах он не рекомендует использовать agile, Владимир назвал миграцию «один в один». Во всех остальных случаях можно рассматривать эту методологию как вариант, выбирая подходящие способы ее реализации в зависимости от стадии развития проекта и его специфики.
Преимущества Agile

Источник: Teradata, 2016
Руководитель направления больших данных российского офиса Teradata Андрей Суворкин напомнил о том, как год назад компания объявила о своей заинтересованности в развитии продуктов с открытым исходным кодом и взяла на себя обязательства по поддержке Presto. Разрабатываемый и используемый Facebook мощный многофункциональный движок SQL-запросов для работы с большими данными позволяет оперативно получать доступ к различным источникам информации. Что за прошедший год сделала Teradata? Создала возможность быстрого старта Presto для тех, кто хочет попробовать, — сделано несколько виртуальных машин, написаны скрипты для администрирования. Кроме того, компания обеспечила интеграцию движка с другими компонентами экосистемы, такими как YARN, Ambari, Teradata QueryGrid. Сейчас ведется активная разработка ODBC и JDBC-драйверов для связи с любыми клиентскими приложениями и работы с BI-системами.
В 2014 г. к Teradata присоединилась компания Think Big, специализирующаяся на оказании консалтинговых услуг в области больших данных. Одним из первых ее российских сотрудников стал Александр Смирнов, Hadoop-евангелист, который рассказал о том, как можно строить эффективную аналитику на базе открытого ПО, в частности на Apache Zeppelin, и даже показал практический кейс реализации проекта на примере данных нефтяной компании. В 1992 г. Teradata создала первое хранилище данных объемом 1ТБ. Сейчас такой объем генерирует небольшой интернет-магазин за неделю работы. Все большее количество организаций вовлекается в процессы, связанные с аналитикой данных, инструменты становятся все более доступными. Think Big помогает заказчикам спроектировать и настроить систему аналитики, которая принесет коммерческую пользу бизнесу. Компания является независимой, применяет широкий спектр открытых решений и нацелена только на максимальную эффективность.
Новая роль владельца экосистемы для аналитики больших данных
Источник: Teradata, 2016
Teradata сегодня активно развивает практику консультирования в сфере проприетарного и свободного программного обеспечения и, по словам Андрея Алексеенко, видит свою роль «не столько как вендора, который имеет лучшую технологию на рынке, сколько как специалиста, который поможет заказчику разобраться во всем многообразии технологий, построить правильную архитектуру и успешно реализовать свои проекты».






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}