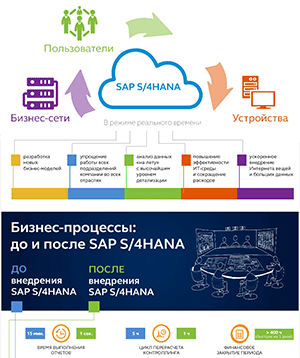
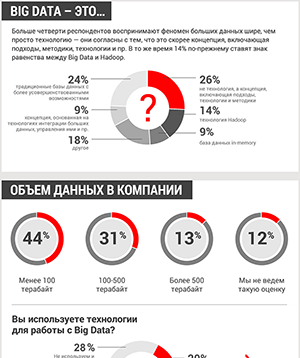
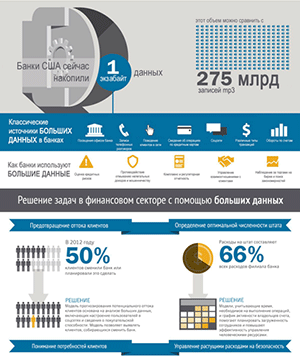
Будущее больших данных – Open Source

Рынок решений больших данных быстро развивается, и активные концептуальные дискуссии здесь сменяются реальными проектами. Практика выявляет узкие места и возможности по их преодолению. Залогом же успешного взросления больших данных станет Open Source, считают в Pivotal.
Постоянный рост объемов информации – не менее постоянно обсуждаемая бизнесом тема, однако пока что компании только учатся извлекать из своих данных пользу. Точнее, до сих пор мало кто умеет это делать. Как показало исследование «Information Generation», проведенное ЕМС и Institute for the Future, 52% компаний из разных стран и отраслей не используют в полной мере накапливаемые данные, либо же вовсе «тонут» в объемах информации. Многие респонденты признают, что пока не вполне соответствуют новым реалиям цифровизации общества и бизнеса. Только 12% могут прогнозировать новые рыночные возможности, столько же – эффективно работают в режиме реального времени на всех уровнях компании.
«Компании все еще плохо работают с данными, – подтверждает Майкл Кукки, руководитель направления продуктового маркетинга Pivotal. – Только 4% компаний во всем мире реально развивают свою аналитику. А им уже надо учиться управлять данными, становиться экспертами в том, как извлекать из них пользу. Возможно, ранее они еще не сталкивались с такими данными – не только с точки зрения объемов, но и с точки зрения типов и форматов».
Самые эффективные заказчики больших данных уже вырастили данные в своего рода актив, считает эксперт. Некоторым даже удается построить решение, которое может генерировать доход – как, например, GE. Однако пока что такие примеры единичны.
При этом цифровизация, по мнению экспертов ЕМС, охватывает уже все сферы деятельности социума и бизнеса – и этот тред будет только усиливаться, в том числе за счет все большего распространения интеллектуальных мобильных устройств, а также всеохватности интернета вещей. Генерируются огромные массивы данных, их обработка требует масштабных вычислительных платформ, с одной стороны, и мощного инструментария для анализа, с другой стороны. И вот как раз в части больших данных рынок все еще определяется с наиболее оптимальными сценариями, накапливая явный дефицит специалистов, но стараясь удерживать быстрый темп.
Возможно, проблему нехватки кадров и высокой скорости роста объемов данных удастся компенсировать, если решения для больших данных будут развиваться на основе открытого кода – в связанной с ним парадигме постоянно разрастающегося и самообучающегося сообщества, которое будет осуществлять поддержку. Апологеты этого подхода считают, что открытое ПО позволит быстрее адаптировать решения к потребностям конкретных компаний, снижая их технологическую зависимость от поставщиков.
Открытая идеология
Решения для больших данных и так уже в значительной мере открыты, считают в Pivotal. Cама компания выпускает Open Source компоненты Big Data Suite, рассчитывая за счет открытых версий значительно расширить свою аудиторию. Кроме того, Pivotal входит в число соучредителей инициативы Open Data Platform (ODP), миссия которой заключается в построении и развитии экосистемы открытых решений для больших данных с участием и поставщиков, и сервис-провайдеров, и заказчиков. Таким образом, Open Data Platform стремится к глобальному повышению зрелости решений для больших данных.
ODP в настоящий момент – это альянс из 15 компаний, среди которых, помимо Pivotal, Hortonworks, GE Software, IBM, Verizon, Infosys, SAS, Capgemini, EMC, Teradata, VMware и другие игроки, сфокусированные на единой enterprise-версии Hadoop. Одна из задач инициативы – стандартизация, которая обеспечивает интероперабельность, с одной стороны, и позволит не допустить излишней фрагментации условного рынка Hadoop, взяв этот процесс под контроль, с другой стороны. «Только так экосистема сможет быстро развиваться», – подчеркивает Майкл Кукки.
Именно Hadoop лежит в основе самой идеологии больших данных – напоминают эксперты компании. Долгое время большие данные ассоциировались как раз с Hadoop и базами данных NoSQL – типа открытых Mongo или Cassandra. Все стартапы и малый бизнес начинают с Hadoop, считает Майкл Кукки. По его словам, весь пакет решений Pivotald в области больших данных со временем будет открытым, как и будущее больших данных в принципе – тоже Open Source.
«С точки зрения платформы, составляющей решения для больших данных сегодня, Open Source уже победил», – считает в свою очередь Роман Шапошник, директор направления Open Source в Pivotal, а также участник Apache Software Foundation.
В пользу успеха инициативы ODP говорят и результаты последнего опроса Future of Open Source – более 50% предприятий подтверждают, что готовы принять участие в развитии открытых решений. Причем на протяжении всех 8 лет проведения опроса респонденты отмечают, что видят главное преимущество участия в открытых инициативах – в возможности коллективно снижать издержки. 68% подтверждают, что им действительно удалось таким образом сократить расходы и повысить эффективность, а 62% говорят о повышении качества своей ИТ-инфраструктуры.
Критерии жизнеспособности
Большая часть рассматриваемых сегодня Open Source решений для больших данных доступны бесплатно – с теми оговорками, которые подразумеваются лицензионными соглашениями типа Apache License, отмечают в Pivotal. Доходы поставщиков начинаются с предложений класса enterprise с дополнительными возможностями. Так действуют, например, Hortonworks и Cloudera применительно к Hadoop или Datastax – к Cassandra. Для MySQL также предусмотрены платные enterprise-версии. Ряд решений NoSQL (в том числе Couchbase и MongoDB) также работают по модели «freemium», монетизируясь за счет enterprise. При этом бесплатным остается доступ к глобальной базе знаний – и возможности для совместного развития решений.
Позиция Pivotal заключается в том, что Open Source становится сегодня залогом успеха любой технологии, включая большие данные. Именно эта парадигма позволяет аккумулировать лучшие ресурсы и быстрее продвигать инновации. А жизнеспособность технологии определяется активным сообществом и развитой экосистемой – тогда у «семи нянек» решения становятся более стабильными, защищенными, их проще внедрять и поддерживать.
Здесь же, правда, скрываются и возможные риски. Все действительно зависит от того, насколько развито сообщество программистов конкретного решение – исходя из чего можно прогнозировать, насколько оно вообще жизнеспособно и перспективно, предупреждает Роман Шапошник. «Клиенты в настоящий момент оценивают продукты по двум параметрам, – поясняет он. – Базируется ли проект на Open Source, и будет ли он завтра присутствовать на рынке. Последний фактор сегодня настолько же важен для оценки, как некогда была важна стандартизация». По его словам, один из признаков успешности подобных OSS-сообществ – например, менеджмент по принципам Linux или Apache Software Foundation.
«Вопрос на повестке дня сегодня не в том, кто из вендоров может поддержать мой объем данных, а в том, какой вендор может поддержать скорость роста моих данных, – комментирует Роман Шапошник. – Ответить на него пока не может никто. Остается найти ответ на вопрос, кто сможет починить, когда что-то сломается. А это, увы, неизбежно произойдет. И вот тут окажется, что починить смогут как раз те вендоры, которые участвуют в Open Source проектах».
Мария Попова