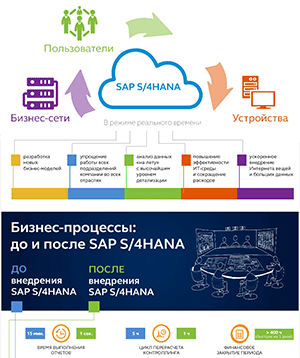
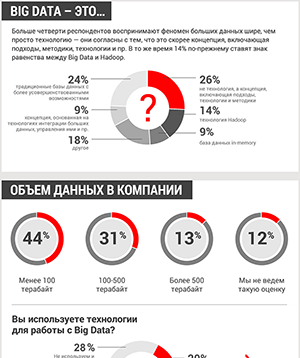
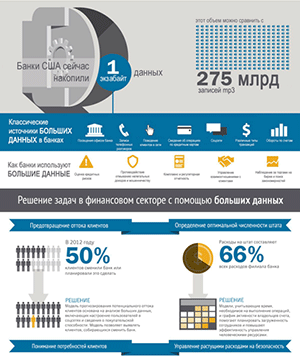
Oracle представила десятку прогнозов в области Big Data на 2017 год
Oracle представила собственный прогноз развития технологий на стыке больших данных и облачных вычислений, в 2017 году. Сегодня к сети подключаются смартфоны и ноутбуки, датчики на машинах, транспортных средствах и устройствах, все эти соединения генерируют огромные объемы данных. Для компаний, способных преобразовывать эти данные и управлять ими, открываются возможности и конкурентные преимущества. Покупатели, изучающие ассортимент розничных магазинов, могут получать на смартфоны скидки или полезную информацию; посетители интернет-магазинов могут воспользоваться персонализированными предложениями согласно их потребностям; производители могут оценить успех новых продуктов за несколько дней, а не недель; водители могут проще получать информацию о доступных парковках с использованием данных реального времени и интеллектуальных устройств.
1. Эпоха повсеместного машинного обучения
Машинное обучение больше не является исключительной прерогативой исследователей данных. Возможность применять машинное обучение к огромным объемам данных значительно повышает его значимость и поддерживает более широкое освоение. Можно ожидать значительного повышения доступности средств машинного обучения в инструментах для бизнес-аналитиков и конечных пользователей. Машинное обучение будет оказывать влияние на взаимодействия пользователей в самых разных областях, от страхования и бытового энергопотребления до здравоохранения и учета времени парковки.
2. Если данные нельзя переместить, можно приблизить облако к данным
Не всегда есть возможность перенести данные во внешний дата-центр. Требования конфиденциальности, регулирующие нормы и требования суверенности данных зачастую препятствуют выполнению таких действий. А иногда объемы данных столь велики, что затраты на их перемещение по сети могут превышать любые возможные выгоды. В таких случаях можно приблизить облако к данным.
В будущем все большему количеству организаций потребуется разрабатывать облачные стратегии для использования данных на различных площадках.
3. Приложения, а не только аналитика для освоения больших данных
Ранние сценарии использования технологий больших данных сосредоточивались главным образом на сокращении ИТ-затрат и схемах аналитических решений. В настоящее время мы видим, что широкое разнообразие отраслевых бизнес-потребностей стимулирует создание нового поколения приложений, основывающихся на использовании больших данных.
Все больше приложений стимулируют применение больших данных.
4. Интеграция интернета вещей с корпоративными приложениями
Интернет вещей (Internet of Things, IoT) — это не просто неодушевленные предметы. Для предоставления пациентам более качественных медицинских услуг, совершенствования обслуживания клиентов через мобильные приложения и других целей требуется мониторинг данных, генерируемых устройствами, с которым люди взаимодействуют. Предприятиям необходимо упростить разработку IoT-приложений и быстро интегрировать такие данные с бизнес-приложениями.
Сочетая новые источники данных с аналитикой реального времени и поведенческой информацией, предприятия разрабатывают новое поколение облачных приложений, способных адаптироваться и обучаться на лету. Влияние будет ощущаться не только в мире бизнесa, и будет проявляться в экспоненциальном росте количества проектов по развитию разумных городов и разумных наций по всему миру.
5. Виртуализация данных «прольет свет на темные данные»
На предприятиях появляется все больше отдельных источников данных на таких платформах, как Hadoop, Spark и СУБД NoSQL. Потенциально ценные данные остаются незадействованными в связи с тем, что доступ к ним (и их поиск) затруднен. Организации понимают, что переместить всё в один репозиторий для обеспечения единого доступа нереально, и что требуется другой подход. Виртуализация данных обеспечит анализ больших данных в реальном времени без необходимости их перемещать.
6. Компании готовятся к выходу на магистраль данных
Технология Apache Kafka укрепляет свои позиции и, судя по всему, достигнет пика популярности в 2017 году. Kafka обеспечивает беспрепятственную публикацию записей о событиях в больших данных, загрузку данных в Hadoop и распространение данных среди потребителей корпоративных данных. Kafka использует традиционную, проверенную архитектуру типа шины, но с очень большими наборами данных и широким разнообразием структур данных. Поэтому она является идеальным решением для загрузки данных в озеро данных и предоставления подписчикам доступа к любым событиям, о которых вашим клиентам следует знать.
Возможно, в 2017 году Kafka станет стремительно развивающейся технологией больших данных.
7. Резкий рост спроса на готовые, интегрированные системы облачных данных
Все больше организаций испытывают потребность в лабораториях данных для проведения экспериментов с большими данными и поддержки инноваций. Однако их развертывание было медленным. Непросто создать лабораторию данных с нуля — на собственной площадке или в облаке. Готовые комплексные решения, интегрирующие такие облачные сервисы, как аналитика, исследование данных, подготовка данных и интеграция данных, упрощают разработку решений собственными силами. В течение всего года ожидается высокий спрос на готовые, интегрированные облачные лаборатории данных.
8. Облачные объектные хранилища как альтернатива Hadoop HDFS
Объектные хранилища имеют множество желаемых атрибутов — доступность, репликация (между накопителями, стойками, доменами и центрами обработки данных), аварийное восстановление и резервное копирование. Это самые дешевые и простые хранилища для больших объемов данных, и они могут поддерживать такие инструменты обработки, как Spark. Технологии объектного хранения становятся репозиторием для больших данных, поскольку они все больше интегрируются с вычислительными технологиями для Big Data и предоставят жизнеспособную альтернативу HDFS-хранилищам для множества сценариев использования. Все они существуют как часть одной многоуровневой архитектуры данных.
9. Облачные архитектуры для глубинного изучения в больших масштабах
Удаление уровней виртуализации. Технологии ускорения, такие как графические процессоры и NVMe-накопители. Оптимальное размещение ресурсов хранения и вычислений. Неблокирующие сетевые взаимодействия с высокой пропускной способностью. Ничто из этого не является чем-то новым. Новое — это их конвергенция. Вместе они позволяют создавать облачные архитектуры, обеспечивающие на порядок большую производительность вычислений, ввода/вывода и сетевых взаимодействий.
Что в результате? Глубинное изучение в значительных масштабах и простота интеграции с существующими бизнес-приложениями и процессами.
10. Безопасность Hadoop как обязательное дополнение
Развертывания и сценарии использования Hadoop перестали быть главным образом экспериментами. Все чаще они становятся критически важными для бизнеса организаций, поэтому безопасность Hadoop стала обязательным требованием.
Вероятно, в будущем вы будете развертывать средства многоуровневого обеспечения безопасности для ваших проектов по использованию больших данных.