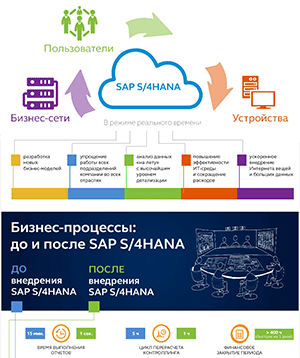
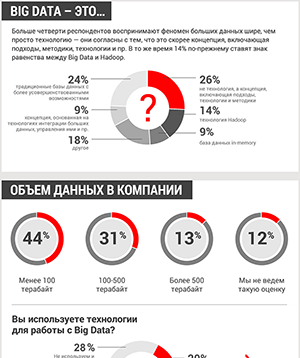
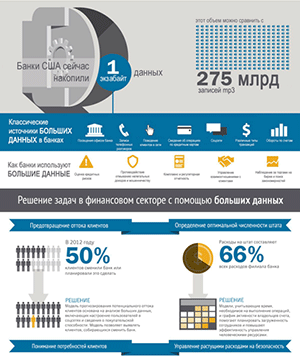
Hitachi Vantara представила платформу для управления данными Lumada Data Catalog
Hitachi Vantara представила платформу для управления данными Lumada Data Catalog. Она расширяет функциональность решений компании для реализации методологии DataOps. Решение обеспечивает заказчикам возможность унификации разнородных данных, рассредоточенных в облаке, инфраструктуре данных, компьютерах и устройствах на границе сети. Технология каталогизации данных Waterline предоставляет заказчикам типовую инфраструктуру метаданных для управления всеми имеющимися данными. Применяя DataOps к унифицированным наборам данных, заказчики могут быстро получать ценную аналитику.
«Операционные, технические и нормативные аспекты проблем, возникающих в связи с увеличением объемов данных, делают каталоги данных все более важным инструментом современных организаций, – отметил технический директор направления цифровых решений Hitachi Vantara Гидо Шредер (Guido Schroeder). – Дополнение комплекса решений Hitachi Vantara для DataOps функциональными возможностями систем Waterline Data – важный шаг, благодаря которому наши заказчики смогут эффективно управлять активами данных в любой информационной среде – от границы до центра инфраструктуры и мультиоблачных систем».
Основатель и технический директор Waterline Data Алекс Горелик (Alex Gorelik), который теперь является старшим научным сотрудником Hitachi Vantara, считает, что технология Waterline станет прекрасным дополнением к комплексу продуктов, технологий и решений Lumada, который обеспечивает конкурентные преимущества заказчикам в любой отрасли: от промышленного производства и энергетики до транспорта и розничной торговли. «Наша технология поможет ускорить реализацию намерения Hitachi Vantara открыть возможности методологии DataOps для создания средств аналитики, управления данными и обеспечения операционной гибкости», – отметил Горелик.
Lumada Data Catalog дополняет продукты комплекса Lumada Data Services и интегрируется с ними, открывая новые возможности – обнаружение данных, сервисы самообслуживания для данных. Каталог данных обеспечивает необходимую прозрачность и предсказуемость благодаря возможности инвентаризации и классификации активов данных. Он позволяет создать требуемый слой метаданных для поддержки критически важных информационных проектов на всех этапах – от подготовки данных до комплексного управления и контроля нормативно-правового соответствия. Решение спроектировано так, что способно расширяться до уровня всего предприятия, и использует высокомасштабируемые и высокопроизводительные компоненты, такие как Spark, Solr и собственную архитектуру на основе агентов либо архитектуру Kubernetes на базе контейнеров. В сочетании с предусмотренными в Lumada возможностями автоматизации на основе политик, такой подход позволит использовать широкий ряд цифровых решений и обеспечит преимущества во множестве отраслей.