Интернет вещей затмил большие данные
Последний отчет Gartner «Цикл зрелости технологий» (Hype Cycle for Emerging Technologies) взбудоражил отрасль отсутствием технологии сбора и обработки больших массивов данных. Свое решение аналитики компании объясняют тем, что понятие «большие данные» включает в себя большое количество технологий, которые активно применяются на предприятиях, частично относятся к другим популярным сферам и «трендам» и, по сути, стали повседневным рабочим инструментом.
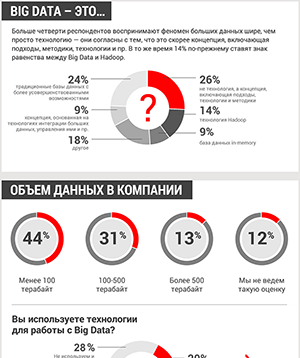
«Изначально понятие «большие данные» расшифровывали через определение из трех «V»: volume, velocity, variety. Под этим термином подразумевалась группа технологий хранения, обработки и анализа данных большого объема, с изменчивой структурой и высокой скоростью обновления. Но реальность показала, что получение выгоды в бизнес-проектах осуществляется по тем же принципам, что и раньше. А описываемые технологические решения сами по себе не создали никакой новой ценности, лишь ускорив обработку большого количества данных. Ожидания были очень высокие, и список технологий больших данных интенсивно рос. Очевидно, что вследствие этого границы понятия размылись до предела», — комментирует Святослав Штумпф, главный эксперт группы маркетинга продуктов «Петер-Сервис».
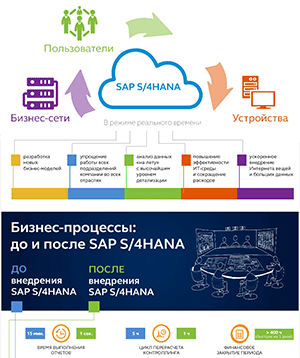
Тема больших данных не исчезла как таковая, а трансформировалась во множество различных сценариев, считает заместитель генерального директора SAP СНГ Дмитрий Шепелявый: «Примерами здесь могут быть ремонты по состоянию, точное земледелие (precision farming), системы по противодействию мошенничеству, системы в медицине, позволяющие на качественно новом уровне диагностировать и лечить пациентов. А также планирование логистической системы и транспортировки в режиме реального времени, усовершенствованная бизнес-аналитика для поддержки и сопровождения основных функций компаний. Один из основных трендов сейчас — Интернет вещей, позволяющий связывать машины между собой (machine-to-machine). Устанавливаемые электронные датчики производят миллионы транзакций в секунду, и необходимо надежное решение, способное трансформировать, сохранить и работать с ними в режиме реального времени».
Еще в мае 2015 г. Эндрю Уайт (Andrew White), вице-президент по исследованиям Gartner, в своем блоге размышлял о том, что Интернет вещей (Internet of Things, IoT) затмит собой большие данные как слишком сфокусированную технологию. Она может породить еще несколько эффективных решений и инструментов, но платформой будущего, которая в долгосрочной перспективе повысит нашу продуктивность, станет именно интернет вещей. Аналогичные идеи еще раньше, по результатам отчета Gartner за 2014 год, опубликовал обозреватель Forbes Гил Пресс (GilPress).
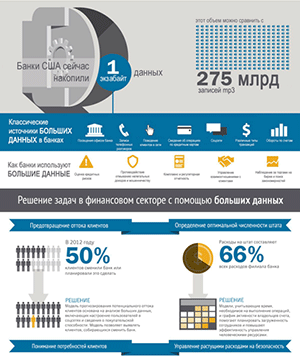
По мнению Дмитрия Шепелявого, сейчас наступила эпоха, когда важно не просто уметь аккумулировать информацию, а извлекать из нее бизнес-выгоду. Первыми к этому выводу пришли индустрии, которые непосредственно работают с потребителем, такие как телекоммуникационная и банковская отрасли, а также ритейл. Теперь процессы взаимодействия выходят на новый уровень, позволяя наладить связь между различными устройствами с использованием инструментов дополненной реальности, и открывают новые возможности оптимизации бизнес-процессов компаний.
«Понятие «большие данные» потеряло интерес для реального бизнеса, на диаграмме Gartner его место заняли другие технологии с более четким и понятным бизнесу звучанием», — считает Святослав Штумпф. Это в первую очередь машинное обучение — средства поиска правил и связей в очень больших объемах информации. Эти технологии позволяют не просто проверять гипотезы, но и искать неизвестные ранее факторы влияния. А также сегмент решений по хранению данных и параллельному доступу к ним (NoSQL Database), по предварительной обработке потоков информации (Marshalling), решения для визуализации и самостоятельного анализа (Advanced Analytics with Self-Service Delivery). Кроме того, считает эксперт, сохраняют свое значение средства интеллектуального анализа данных (Business Intelligence и Data Mining), выходящие на новый технологический уровень.
«В нашем
понимании большие данные никуда не исчезли и не трансформировались, — комментирует
тему пресс-служба «Яндекса». — Для обработки
больших массивов данных мы используем те же технологии и алгоритмы, что применяем
в интернет-поиске, сервисе «Яндекс.Пробки», в машинном переводчике, в рекомендательной
платформе, в рекламе. Алгоритмы базируются на нашем умении накапливать, хранить
и обрабатывать большие объемы данных и делать их полезными бизнесу. Области применения
Yandex Data Factory не ограничены — главное, чтобы были данные для анализа. Сейчас
у нас в фокусе ритейл, финансы, логистика, телеком, энергетика, ЖКХ, нефтегаз, аэрокосмическая
отрасль. Пилотные проекты дали нам первичный опыт в этих отраслях, а сейчас у нас
сейчас более 20 проектов в работе на разной стадии».