Большие данные помогут создать искусственный интеллект
Системы больших данных могут оказаться недостающим ингредиентом для достижения одной из наиболее важных глобальных целей всей ИТ-индустрии – создания полноценного искусственного интеллекта (ИИ), считают эксперты. В течение последних месяцев появился целый ряд новых стартапов, главной целью которых является применение новых подходов к анализу больших данных с использованием машинного обучения, естественного распознавания языка и других техник ИИ, которые разрабатывались в течение последних лет.
В частности, один из таких стартапов под названием Cognitive Scale применяет подход к машинному обучению от IBM Watson для извлечения информации из огромного количества так называемых «темных данных», «похороненных» в интернете среди, например, обзоров с сервиса Yelp, пользовательских фотографий и сообщений на форумах, а также в корпоративных сетях среди файлов с финансовыми отчетами или бухгалтерских документов. Cognitive Scale предлагает своим клиентам набор API, которые бизнесы могут использовать для подключения к алгоритмам, предназначенным для улучшения эффективности поиска и анализа информации.
Еще один стартап – Zintera – также пытается коммерциализировать вышеупомянутые когнитивные технологии. Zintera занимается разработкой платформы «глубокого» машинного обучения, и первые демонстраци ее работы многие эксперты уже назвали весьма впечатляющими.
Глубокое обучение ИИ на базе систем больших данных, несомненно, является важным приоритетом и для топ-менеджеров интернет-гиганта Google. Недавно эта компания приобрела два стартапа, созданных выпускниками Оксфордского университета и работающих в данном направлении, – Dark Blue Labs и Vision Factory. Команды данных стартапов в составе Google будут работать над технологиями машинного распознавания изображений и естественного распознавания языка.
Стартап Sumo Logic, в свою очередь, нашел способ применения технологий машинного обучения к большим объемам компьютерных данных. Новая версия аналитической платформы от Sumo Logic умеет анализировать лог-файлы для обнаружения проблемных приложений. «Глубокое машинное обучение само по себе, если оно производится в научных кругах, не имеет такого же эффекта, как если бы оно проводилось в Google, масштабировалось и интегрировалось в новый продукт», – отметил Биу Кронин (Beau Cronin), глава подразделения по разработке искусственного интеллекта в составе компании Salesforce.com.
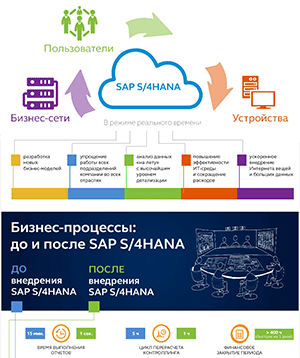
Развитие искуственного интелекта позволит повысить уровень сервиса в различных индустриях, считают эксперты. «Речь по сути идет об утилизации новых технологических решений для индивидуализации обслуживания, но на основе больших данных, – прокомментировал для CNews Дмитрий Армяков, генеральный директор SAP Labs СНГ. – SAP совместно с экосистемой своих партнеров работает над схожими задачами, решая их с помощью нашей платформы SAP HANA, облачных вычислений и технологий предсказательной аналитики. Большие перспективы мы видим не просто в больших данных или в искусственном интеллекте, а в возможности использования этих инструментов в самом настоящем реальном времени, по сути в потоке данных. Такие технологии могут иметь хорошие перспективы в России. Математическая и программистская школа у нас сильны, а для таких решений это важно».