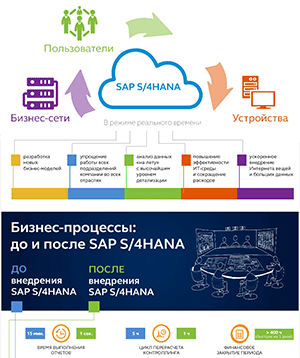
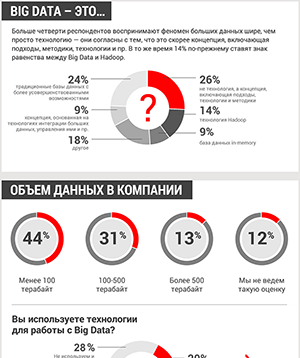
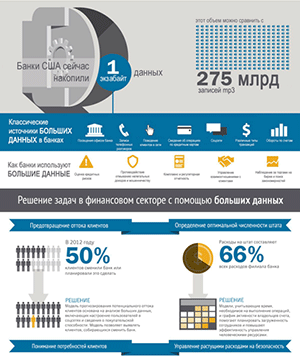
Бизнес осознал потребность в зрелом управлении данными

Компания проходит несколько стадий на пути к пониманию того, что им нужно зрелое управление данными. Большие данные и аналитика существенно помогают бизнесу. О том, как оптимизировать и монетизировать данные с помощью систем управления, с какими сложностями можно столкнуться, как получить пользу от внедрения, как узнать своего клиента лучше с помощью цифровых технологий, говорили участники секции «BI и большие данные» на CNews FORUM 2019: Информационные технологии завтра.
Кирилл Дубовиков: Правильная постановка задачи может определять до 80% успеха
О развитии технологий искусственного интеллекта для обработки больших данных рассказал Кирилл Дубовиков, технический директор «Синимекс Дата Лаб».
CNews: Что обычно понимается под технологией Data Science/Big Data? Что это на практике?
Кирилл Дубовиков: Data Science и Big Data представляют из себя две разные дисциплины. Data Science решает бизнес-задачи с помощью сбора, обработки и анализа данных. Big Data – это больше про инженерию, когда есть потребность в обработке большого объема данных, подсчете или соединении нескольких их источников.
В программном обеспечении есть такое понятие как вертикальное и горизонтальное масштабирование. Вертикальное означает, что масштабирование происходит за счет добавления мощности к существующей машине. Горизонтальное – за счет еще одной машины в вашем пуле ресурсов. На практике вертикально масштабировать намного дороже и сложнее, чем горизонтально: купить 10 компьютеров дешевле, чем в 10 раз улучшить сервер по характеристикам.
Big Data – это технологии и инженерные практики, которые позволяют собрать большие объемы данных, которые не помещаются на один компьютер, и обработать их на большом количестве машин. Зачастую, Big Data технологии помогают решать задачи в Data Science. К примеру, на многих проектах требуется обрабатывать большое количество данных, которые не посчитаешь на одном сервере, или же требуется параллельно выполнить много ресурсоемких расчетов.
Big Data – это технологии и инженерные практики, которые позволяют собрать большие объемы данных, которые не помещаются на один компьютер, и обработать их на большом количестве машин. Зачастую, Big Data технологии помогают решать задачи в Data Science. К примеру, на многих проектах требуется обрабатывать большое количество данных, которые не посчитаешь на одном сервере, или же требуется параллельно выполнить много ресурсоемких расчетов.
CNews: В каких сферах Data Science используют чаще всего? Какие тренды можно наблюдать на российском рынке данных технологий?
Кирилл Дубовиков: В настоящее время область применения технологий практически ничем не ограничена: во всем мире, и в России в том числе, неуклонно растет количество собираемой информации. Каждый день в таких сферах как производство, ритейл, банкинг, ИТ, логистика и медицина копится множество данных. В то время как методики, используемые в Data Science и в статистике, универсальны и применимы к любым данным и к решению многочисленных прикладных задач. На российском рынке Data Science используют по большей части те компании, которые заботятся о цифровой трансформации и собирают большие объемы данных. К ним, как правило, относятся производство, ритейл и финансовый сектор.
В банковском секторе алгоритмы машинного обучения используются в управлении рисками и в сфере безопасности, например, в случаях махинаций с картами и счетами.
Технология способна заметить аномалии, исходя из накопленной истории случаев мошенничества, и предупредить незаконные действия. При этом, в банках уже давно существуют fraud-detection системы, основанные на жестких правилах, способные распознать случай мошенничества при помощи заранее определенных критериев оценки.
С другой стороны, модели машинного обучения позволяют разработать систему с нечеткой логикой, которая ищет подозрительные действия и нетиповые операции, совершаемые клиентами банка, заранее не занесенные в fraud-detection систему. Совмещение жестких правил и алгоритмов Data Science дает преимущество – система становится гибкой и начинает обнаруживать новые поведенческие шаблоны злоумышленников. Также в финансовой сфере подобные технологии используются для тарификации, персонификации кредитных предложений и вкладов, предпринимаются попытки для скоринга юридических лиц.
В ритейле алгоритмы машинного обучения тоже востребованы: можно наблюдать динамику передвижения людей в магазине, выкладку товаров на полках. В сфере торговли набирает популярность технология прогнозирования спроса при помощи моделей машинного обучения, особенно это касается вопросов логистики и бережливого подхода к ней. К примеру, если у компании есть десятки тысяч торговых точек, и продуктовый каталог составляет сотни тысяч записей, человеку уже невозможно составить точное распределение товаров на основе прогноза спроса по всем позициям. А алгоритмы машинного обучения удачно справляются с этой задачей. Яркий пример, где сокращение логистических издержек играет ключевую роль – это аптеки. Если лекарства привозятся в аптеку, то в соответствии с внутренними процессами фармакологических компаний, они в ней регистрируются, и дальше их перевозить нельзя. В случае, если товара осталось много и срок годности подходит к концу, то нельзя развезти лекарства по аптекам, где наблюдается дефицит. По правилам, партия лекарств сначала возвращается на центральный склад, проходит ресертификацию, и только потом отправляется в другую аптеку. При таких условиях точность алгоритмов играет важную роль.
В производстве часто возникает потребность в решении задачи предиктивного обслуживания – способа заранее определить неполадки в дорогостоящем производственном оборудовании. С помощью алгоритмов можно спрогнозировать, что может пойти не так, и уменьшить длительность и количество ремонтов оборудования, оберегая цикл производства от непредвиденных остановок. Данные для машинного анализа собираются с большого количества сенсоров, измеряющих состояние этих установок.
Также в сфере промышленности, к примеру, в нефтехимической отрасли, популярна тонкая настройка производственных процессов, где на одном из этапов производства происходит химическая реакция внутри сложного аппарата. Зачастую существует зависимость от условий внешней среды и особенностей сборки оборудования, поэтому каждый производственный процесс имеет уникальные характеристики и требует тонкой настройки. Алгоритмы могут подстраиваться под все заданные условия, находить взаимосвязь между внутренними и внешними факторами, подстраивать процесс так, чтобы, например, увеличить полезный выход реакции. Важным фактором является то, что они могут следить за реакцией и условиями 24/7 без остановок и с меньшими затратами, в сравнении с существующими процессами мониторинга.
CNews: От чего зависит успешность реализации проектов на базе данных технологий? Можете привести пример успешного проекта?
Кирилл Дубовиков: Успешность проектов определяют много факторов. Дисциплина достаточно молодая, и в ней происходит много изменений. С точки зрения управления проектами, важно понимать разницу между методологиями управления проектами по разработке ПО и проектами по анализу данных.
Правильная постановка задачи крайне важна для проектов по анализу данных: она может определять до 80% успеха. Здесь, как и в проектах по разработке, присутствует принцип текучих абстракций: с одной стороны, заказчик при постановке задачи не должен знать все детали технологии, с другой стороны, неточная формулировка может очень сильно повлиять на способ решения задачи, достигнутые результаты и, в конце концов, на бизнес-процессы. Поэтому тем, кто ставит задачи и разрабатывает идеи, важно получить экспертизу в базовых понятиях анализа данных и составить общее понимание о возможностях алгоритмов машинного обучения. При этом не обязательно разбираться в сложных доказательствах теорем. Главное, чтобы было представление о том, какую бизнес-ценность могут принести данные технологии в существующих условиях, какие задачи могут решаться, а какие лежат за гранью возможностей алгоритмов машинного обучения.
Успешно реализованным проектом с хорошей формулировкой задачи и корректными ожиданиями можно назвать проект для одного из наших клиентов – зарубежной микрофинансовой организации. В рамках проекта требовалось реализовать скоринговую модель для оценки риска невозврата долга. Нетиповой особенностью проекта было то, что история транзакций клиентов была недоступна: ее приходилось восстанавливать, анализируя текстовые сообщения, переданные с телефона пользователя по его согласию. В дополнение к этому, мы собрали большое количество данных из социальных сетей и государственных порталов, на основе которых создали скоринговую модель. Заказчики оказались довольны.
Отличительная черта нашей команды в том, что мы умеем реализовывать надежные системы для промышленного использования и не останавливаемся на стадии реализации модели. У компании больше 20 лет опыта и экспертизы в разработке ПО, поэтому мы решаем задачу более широко: смотрим на нее как на ИТ-систему, которую нужно реализовать таким образом, чтобы она приносила пользу бизнесу. Разработка модели машинного обучения – лишь часть процесса. Мы всегда стараемся сформулировать цель проекта так, чтобы не только разработать качественную модель, но и поставить заказчику законченное решение бизнес-задачи.
CNews: С какими проблемами чаще всего встречаетесь при реализации проектов с использованием Data Science/Big Data?
Кирилл Дубовиков: Существуют проблемы, связанные с инфраструктурной и инженерной составляющей. К проектам по анализу данных часто относятся как к научным исследованиям, но на самом деле за ними должен стоять хорошо отлаженный инженерный процесс, который позволяет сотрудникам не тратить время на рутинные операции. К примеру, в разработке ПО есть инженерная практика DevOps, которая занимается автоматизацией процесса поставки ПО, начиная от сборки и заканчивая передачей в промышленную эксплуатацию.
Для Data Science проектов DevOps применять сложно, так как весь инструментарий нацелен на работу с исходными кодами, а в аналитических проектах есть еще одна неотъемлемая составляющая – данные. Долгое время не существовало хороших систем для версионирования данных, а это важно, так как в Data Science проектах используется большое количество взаимосвязанных стадий обработки данных. Версионирование данных важно и для экспериментальной части проекта, где нужно обеспечивать воспроизводимость каждого эксперимента. Также большой проблемой является фиксация результатов экспериментов. К примеру, специалист по анализу данных может осуществлять сотни экспериментов в неделю. Через месяц работы становится невозможно определить, какие результаты значимые, а какие нет.
Для решения этих задач стали разрабатываться специализированные системы трекинга экспериментов и контроля версий данных. Далеко не все команды знают и умеют применять эти инструменты, что отрицательно сказывается на проектах. При этом важно не только использовать инструменты, но и связать их в единый инженерный процесс.
CNews: Что ждет данную технологию в будущем? Что может ее заменить?
Кирилл Дубовиков: Сейчас мы находимся на стадии использования слабого искусственного интеллекта (Weak Artificial Intelligence) – алгоритмов, решающих когнитивные задачи. Например, простые способности человека – распознавание объектов на изображении или речь. Но на этом возможности алгоритмов не ограничиваются. К примеру, с их помощью можно решать задачи, которые человеку не под силу: вычислить взаимосвязи в данных, в которых множество таблиц и колонок, найти шаблоны принятия решений и обобщить их. На выводы, которые человек будет делать месяцы или годы, рутинно обрабатывая тысячи строк данных, машина потратит секунды. Разумеется, данные технологии еще далеки от истинного искусственного интеллекта (Strong Artificial Intelligence) – компьютерной системы, способной мыслить и рассуждать как человек. Реализация истинного ИИ все еще принадлежит к области научной фантастики.
Область продолжает развиваться, ученые открывают способы решения новых задач и улучшают качество решений уже работающих алгоритмов. Многие технологии уже давно вышли на уровень, способный приносить пользу бизнесу. Тем не менее, степень внедрения этих технологий все еще низкая, во многом из-за того, что дисциплина анализа данных еще не успела полностью превратиться из науки в ремесло. Мы в «Синимекс Дата Лаб» учавствуем в процессе индустриализации анализа данных и машинного обучения для того, чтобы с каждым годом все больше компаний могли извлекать пользу из данных.