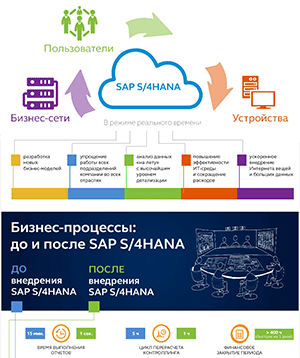
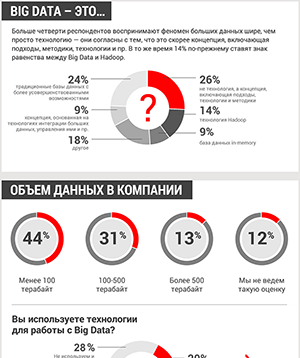
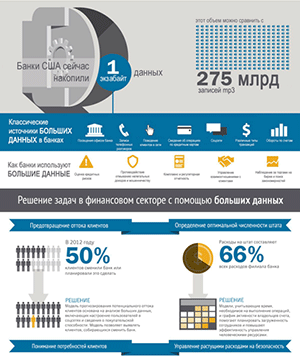
«Сбер» открывает доступ к огромному набору речевых данных на русском языке
«Сбер» объявил об открытии доступа к датасету Golos — самому большому размеченному вручную набору речевых данных на русском языке, включающему 1240 часов аудиоданных, а также обученной на них модели распознавания речи, которая показывает точность, сравнимую с человеческой. Датасет можно скачать на сайте Github.
Данные могут быть использованы для распознавания и синтеза речи. «Сбер» предоставляет их по лицензии, допускающей использование в исследовательских и коммерческих целях, а это более одного миллиона коротких записей русской речи и соответствующие транскрипции.
Над датасетом работала команда Sberdevices: создание такой базы стало возможным благодаря разработке семейства виртуальных ассистентов Салют. Было сгенерировано более 1240 часов речи, похожей на запросы пользователей. Аудиофайлы записаны при помощи краудсорсинговой платформы и специальной студии. Датасет Golos составляют обезличенные записи, прослушанные и размечены вручную. Точная разметка, полученная благодаря тройному перекрытию, позволяет создавать качественные речевые технологии и продукты.
Помимо данных, «Сбер» выкладывает обученную на них модель распознавания речи. Она обучалась с использованием мощностей суперкомпьютера «Кристофари» от «Сбера» на 16 видеокартах Nvidia Tesla V100 в течение 8 дней. Доступная для использования акустическая модель QuartzNet 15x5 была обучена на данных датасетов Golos и Common Voice, а языковая модель KenLM построена на Common Crawl и аннотациях Golos.
«Открытие датасета Golos — это очень важный шаг для развития речевых технологий в России, и мы в «Сбере» рады, что можем применить свой опыт в этой области и продолжить наш тренд делиться своими наработками и технологиями с разработчиками и научным сообществом. Речевые технологии сейчас очень активно внедряются во всех сферах. При этом уже существует масса открытых данных на английском языке, но такого качественного русскоязычного датасета не было. Теперь же есть доступные данные и на русском языке, которые можно использовать для распознавания и синтеза речи, а обученная на них модель показывает очень высокое качество. Мы верим, что датасет Golos даст возможность научному сообществу России двигаться ещё быстрее в совершенствовании русскоязычных речевых технологий», – сказал Денис Филиппов, CTO Sberdevices.