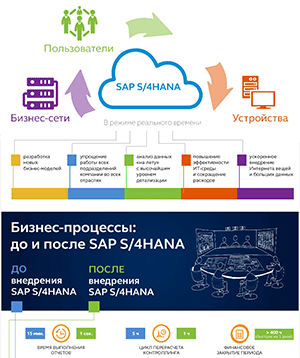
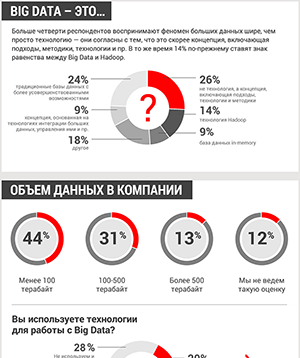
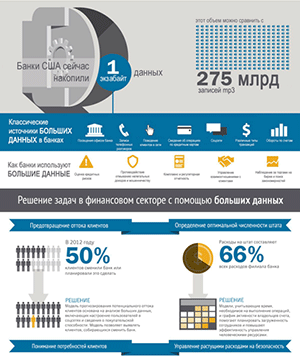
Главная проблема больших данных – сами данные стали проблемой

Если большие данные – это возможность для компаний подняться в конкурентной борьбе, то темпы их роста – то, что заставляет задумываться о расходах. Переход к технологиям интернета вещей потребует немалых затрат на хранение и обработку информации. Как не потратить на это все деньги и получить мощные аналитические инструменты? Заместитель директора центра отраслевых и бизнес-решений RedSys Николай Кузнецов предлагает обратить внимание на преимущества распределенных баз данных.
CNews: Что сегодня является главным драйвером роста объемов корпоративных данных в мире?
Николай Кузнецов: Основной темп задает сфера управления ожиданиями клиентов в банковской отрасли, телекоме, ритейле. Все активные пользователи интернета сегодня подключены к интернет-магазинам, они указывают свои данные в личных кабинетах, оставляют следы при просмотрах и заказах товаров, и на этой основе уже можно собирать аналитическую информацию. Иногда нет нужды даже в получении персональных данных, настолько точно современные аналитические системы устанавливают личность человека по психотипу и другим особенностям.
Эти инструменты уже используются и в целях безопасности, если нужно, например, найти человека, который в соцсетях логинится под разными профилями и оставляет определенные записи. Например, запущена информация в Сети, что нужно срочно снимать деньги с вкладов в каком-либо из банков. Специализированные средства могут выявить источники информации и определить, что это целенаправленная атака на банк.
CNews: Появился ли уже в России интернет вещей, который, как считают, породит еще большую волну данных?
Николай Кузнецов: Если мы говорим об интернете вещей, относящемся к миру людей, то можно сказать, что он уже создан: на каждого пользователя интернета уже приходится несколько подключенных устройств. В отношении индустриального интернета вещей об этом только начинают говорить. Его реализация в промышленности еще требует больших вложений: отдельные его элементы внедряются, но даже до «экватора» мы еще не дошли.
CNews: Готовы ли классические системы к интернету вещей, к новым объемам хранимых и обрабатываемых данных?
Николай Кузнецов: Существующие сегодня системы готовы к этому только до определенного уровня, на скорость их устаревания оказывают критическое воздействие два фактора. Первый – структурированность данных становится все более условной. Растет количество аналитических отчетов, которые требуются компаниям. Еще недавно они хотели знать о пользователях немногое: их возраст, пол, семейное положение, социальный статус и регион проживания. Сейчас же потребности существенно возросли: нужно знать тип устройства, с которого человек выходит в сеть (с дорогого или дешевого), какой трафик он скачивает, какие сайты посещает и т.д. И напрямую автоматически в классическую базу данных всю эту информацию отправить не получится.

Раньше над созданием моделей данных для различных целей трудились аналитики, это занимало много времени – месяцы, а иногда и годы. Перечень данных и возможности были невелики, но все равно любые изменения сопровождались большим объемом работы. Допустим, в компании обнаруживали новую тенденцию в отрасли и требовали от аналитиков сделать так, чтобы можно было посмотреть данные в новом разрезе. Пока изучалась задача, анализировались справочники, имеющиеся отчеты на наличие нужных данных, создавался новый отчет, могло пройти от двух недель до полугода. Сейчас же стало еще сложнее работать. И объем информации увеличился, и ее структура может часто меняться.
Второй фактор – деньги. Растет динамика рынков, на которых работают компании. Технологии дали возможность отслеживать изменения на них буквально в режиме реального времени. И, работая с классическими базами данных, мы уже не можем так быстро предоставлять бизнесу данные, чтобы он принял решение и отреагировал. Сами базы данных могут увеличиваться в размерах и дальше, но для работы с ними приходится приобретать дополнительное дорогостоящее оборудование. Кроме того, стоимость сопровождения промышленных баз данных пропорционально зависит от их объема. И таких «подводных камней» достаточно много в области онлайн-обработки большого количества данных, где базы содержат сотни терабайт при ежедневном потоке входящей информации в сотни мегабайт. Все это заставляет искать новые средства для эффективной работы с информацией.
CNews: Может ли спасти компанию использование нескольких различных аналитических систем, обслуживающих нужды отдельных подразделений? Достаточно много крупных компаний внедряет более одной системы, в зависимости от своих потребностей в аналитике.
Николай Кузнецов: Разделение систем не поможет. Проблема в том, что объем баз данных увеличивается не пропорционально. База, с которой работает система одного департамента, может вырасти ненамного, а в двух соседних она увеличится в пять раз или на порядок. Это все равно заставит компанию принимать меры: менять оборудование или даже сами системы.
Кроме того, часть отчетов для руководства требует данных из разных баз, и их придется собирать вручную. Возникает еще одна проблема: раньше была одна база данных и одна группа аналитиков, которые понимали, как она устроена, а сейчас их несколько. Они тоже растут и для работы требуют специалистов. Для того, чтобы увидеть один общий показатель, придется вручную собирать данные. Поэтому на определенном этапе разделение может помочь, но быстро выяснится, что такой подход только все усложнил. Сейчас, наоборот, стремятся интегрировать, делать единые сервисы для баз данных.
Проблема больших данных заключается в том, что данные стали проблемой. За их содержание нужно платить, а как правильно их использовать, мало кто знает.
CNews: Что нужно делать компаниям? Какие подходы помогут справиться с проблемой больших данных?
Николай Кузнецов: Основываясь на опыте нашей компании в работе с открытой платформой для вычислений на базе Hadoop, я могу сказать, что многие проблемы решаются после перехода на работу с распределенной базой данных. В частности, Hadoop – свободно распространяемое ПО, за него платить не надо. Приходится доплачивать за права на коннекторы к системам ведущих вендоров. Смысл ее в том, что механизм распределяет базу по различным устройствам. Причем это могут быть не только уже существующие серверы, которые при расширении традиционной базы данных пришлось бы заменять на более мощные или подвергать апгрейду – база может самостоятельно распределяться и по настольным компьютерам, ноутбукам. Один из наших клиентов нашел применение таким образом целому парку компьютерного оборудования, от которого собирался уже избавляться. От потери данных в случае выхода оборудования из строя данные застрахованы при помощи репликации – обычно на три устройства.
Еще одно преимущество – информация вводится не людьми, заполняющими нужные поля, а сервисами, работающими на устройствах. Мы просто прописываем правила преобразования информации. При этом данные очищаются, быстро и правильно распределяются. Благодаря этому сводный отчет можно получить уже на следующий день.
Добавление новых отчетов в систему происходит более гибко и автоматизировано. Достаточно обратиться к внутреннему сервису на конечном инструменте BI и добавить аналитику с его помощью. В итоге такой подход обеспечивает хорошую масштабируемость и более низкую цену по сравнению со специализированными вендорскими программо-аппаратными комплексами, которые рассчитаны на высокую производительность при работе с большими базами данных.
CNews: В вашей практике есть примеры реальных проектов?
Николай Кузнецов: В качестве примера можно назвать проект в одном из крупнейших операторов связи. Там мы на базе специализированной системы сделали решение для антифрод-контроля за использованием трафика дилерами. Система анализирует события и информирует о тех, когда дилер может, например, перепродавать трафик своего провайдера. Важно, что это происходит в режиме онлайн, потому что через полгода такая аналитика уже никому не нужна – ее задача работать оперативно и предоставлять отчеты максимум к концу месяца. Заказчик работает с большим числом дилеров на огромной территории, и проведение расчетов получается весьма трудоемким.
Еще один проект – создание распределенной базы данных на Hadoop у другого корпоративного заказчика в секторе телеком. Она собирает данные об абонентах интерактивного телевидения – онлайн считается трафик, пользователи, их действия в системе. Плюс – расчет взаиморасчетов с партнерами, комиссий и т.д.
Промышленность также активно интересуется этими технологиями, потому что непосредственно сталкивается с проблемой больших данных. Ей интересны и возможности предиктивной аналитики, помогающей в реальном времени управлять производственными процессами и предотвращать аварии. Для успеха проекта необходима информация, исторические данные – иногда от тысяч датчиков. Хранение этих данных и их обработка тоже требуют расходов. Компании стараются инвестировать в такие проекты как можно более эффективно с точки зрения отдачи от затрат, и у нас есть, что предложить для решения этих задач.