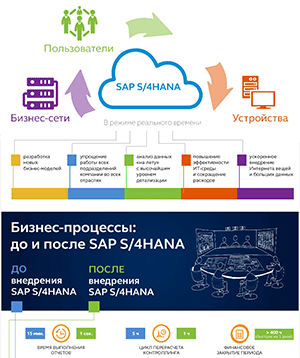
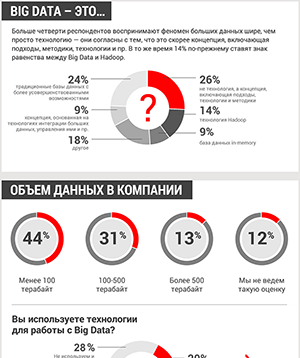
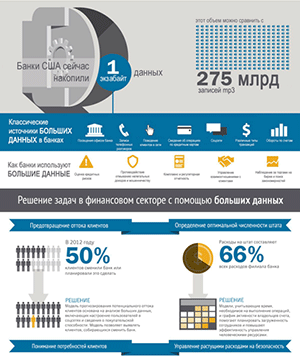
Как ИИ помогает монетизировать большие данные
Сможет ли искусственный интеллект заменить инженеров на стройке, зачем на производстве роботы и дроны, почему почти все проекты, связанные с внедрением искусственного интеллекта, проваливаются? Об этом говорили участники организованной CNews Conferences конференции «Искусственный интеллект 2022». Представители разных сфер бизнеса и промышленных отраслей рассказали, как используют машинное обучение и ботов в своей практике.
Георгий Каспарьянц: Основные проблемы — это «сырость» данных, некачественная разметка и неполный дата-сет
Развитие технологий машинного обучения прямо зависит от качества данных, на которых базируется работа нейросети. Как организовать процесс их сбора и очистки для того, чтобы впоследствии не столкнуться с серьезными проблемами, рассказал Георгий Каспарьянц, основатель и генеральный директор LabelMe.
CNews: С какими проблемами качества данных приходится сталкиваться компаниям?
Георгий Каспарьянц: Личный опыт позволил выявить 3 ключевые проблемы, связанные с качеством данных. Во-первых, это «сырость» данных — когда данные не приведены к единому виду. Например, присутствуют битые картинки или видео, разные разрешения и форматы или json-файлы содержат ошибки. Это очень распространенные проблемы, но, к счастью, они не влияют на точность модели. Только прибавляют работы вашим дата–сайентистам.
Во-вторых, некачественная разметка — когда размечены не все классы или они размечены с логическими ошибками, извлечены не все сущности, границы в сегментации неточные и так далее. Если не предпринять меры по исправлению, на выходе можно получить неточную модель.
В-третьих, полнота дата-сета — когда набор данных содержит не все инвариантные преобразования объектов. Например, для задач детекции поз нет данных о людях с поднятыми руками. Из-за этого нейросеть может попросту не работать с некоторыми из основных задач.
CNews: Каковы самые популярные причины этих проблем?
Георгий Каспарьянц: Чтобы ответить на этот вопрос, нужно разобрать каждую проблему. «Сырость» данных чаще всего возникает из-за децентрализованной системы выполнения. Например, данные собирались или размечались с помощью стороннего исполнителя, каждый из которых мог отступить от технического задания, поскольку это никак не контролировалось. Также разметчики могут использовать разный софт, из-за чего отличаются форматы выходных данных. И, конечно же, отсутствие тщательной проверки.
Проблемы с качеством разметки чаще всего возникают, когда ее выполняют люди без опыта. Они могут не знать все нюансы. Например, как разметить объект, который перекрывает другой объект. Также важна точность технического задания: если оно прописано не детально, то исполнитель может допустить ошибку, даже не подозревая об этом. В масштабах объемного дата-сета это может стать критическим недочетом.
Неполнота данных чаще всего возникает тогда, когда на стадии формирования технического задания не учитываются различные кейсы используемой технологии. В зависимости от задачи, которую должен решать алгоритм, могла быть допущена логическая ошибка, не учитывающая инвариативные преобразования: ракурсы, позы, освещение и так далее.
CNews: Какие способы их решения вы предлагаете?
Георгий Каспарьянц: Чтобы избежать «сырости», необходимо стандартизировать проверку данных. Например, в LabelMe этот этап обязателен — на нем отсеиваются проблемные файлы и отправляются на доработку. Помимо разметчиков мы выделяем команду проверяющих, которые занимаются исключительно валидацией.
Что касается разметки, необходимо допускать к работе только разметчиков с опытом и в мельчайших деталях прорабатывать техзадание. Нужно постараться предвидеть проблемы, которые могут возникнуть в ходе аннотации, и дать исполнителям решение или подробную инструкцию. Мы в LabelMe формируем отделы по специализациям. Разметчик, который хорош в CV, занимается CV. Таким образом мы используем сильные стороны наших специалистов для решения конкретных задач.
С полнотой данных возникает самая большая проблема. Если данные неполные, компании приходится их дополнительно собирать и размечать. Это замораживает весь процесс и отбрасывает разработку ML-продукта на первый этап. Начиная все с нуля, важно внимательно изучить смежные кейсы, дополнить техзадание и оперативно приступить к доработкам дата-сета. Если и во второй раз возникнут логические проблемы при составлении техзадания, то придется вновь повторять всю процедуру. Специалисты LabelMe углубляются в каждый заказ и предлагают внести правки в логику техзадания. Таким образом мы экономим средства и время наших клиентов.